Diffusion Model 완벽 이해하기
생성형 AI 시장의 중심 기술은 GAN에서 Diffusion Model로 빠르게 이동했다. 현재 Stable Diffusion, Midjourney, Sora 같은 최신 생성 모델 대부분이 Diffusion 구조를 기반으로 발전하고 있다. 단순 이미지 생성 품질뿐 아니라 학습 안정성, 확장성, 멀티모달 연결 구조까지 포함해 생성 AI 전체 흐름이 바뀌고 있다는 점이 중요하다.
Diffusion Model은 원본 데이터에 노이즈를 추가한 뒤 다시 복원하는 과정을 반복 학습한다. 이 복원 기반 접근 덕분에 기존 GAN 구조보다 안정적인 학습과 높은 품질의 생성 결과를 동시에 확보할 수 있게 되었다.
생성형 AI의 흐름은 왜 GAN에서 Diffusion으로 이동했을까
초기 생성형 이미지 시장은 GAN 중심 구조였다. Generator와 Discriminator가 경쟁하며 이미지를 생성하는 방식 덕분에 상당히 사실적인 결과물이 가능했다.
하지만 실제 학습 과정은 매우 불안정했다. 생성기와 판별기 균형이 무너지면 특정 패턴만 반복 생성하는 Mode Collapse 현상이 자주 발생했다. 해상도가 높아질수록 튜닝 난이도도 급격히 증가했다.
반면 Diffusion Model은 경쟁 구조 대신 확률 기반 복원 구조를 사용한다. 이미지에 점진적으로 노이즈를 추가하고 다시 제거하는 과정을 학습하기 때문에 데이터 분포 전체를 더 안정적으로 학습할 수 있다.
| 비교 항목 | GAN | Diffusion Model |
|---|---|---|
| 학습 구조 | 생성기·판별기 경쟁 | 노이즈 복원 기반 |
| 학습 안정성 | 상대적으로 불안정 | 비교적 안정적 |
| 생성 품질 | 빠르지만 불안정 가능 | 세밀하고 안정적 |
| 확장성 | 고해상도에서 어려움 | 멀티모달 확장 용이 |
특히 텍스트 조건부 생성(Text-to-Image) 분야에서 Diffusion 구조가 폭발적으로 성장했다. 자연어와 이미지 관계를 세밀하게 연결할 수 있었고, 이는 Stable Diffusion과 Midjourney 같은 모델 성장으로 이어졌다.
산업 구조 측면에서도 변화가 컸다. GAN 시대에는 대규모 GPU 자원을 가진 기업 중심으로 생성 모델이 운영됐지만, Diffusion 이후에는 개인 개발자와 오픈소스 커뮤니티까지 생성 AI 생태계에 참여하게 되었다.
Diffusion Model의 핵심 원리: 노이즈를 추가하고 다시 복원하는 과정
Diffusion Model의 핵심은 “완전한 랜덤 노이즈 상태에서 이미지를 복원하는 과정”에 있다.
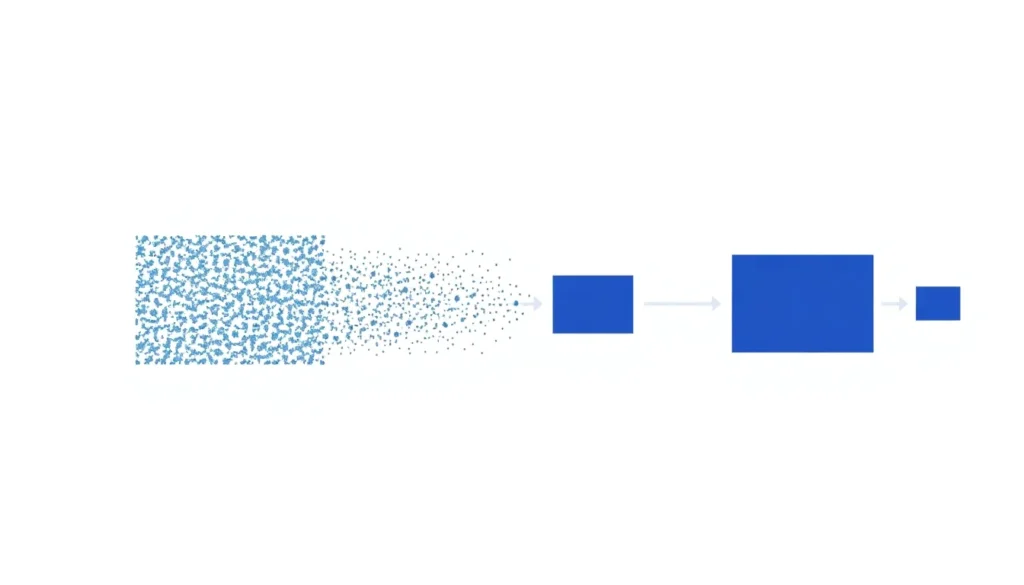
가장 이해하기 쉬운 비유는 심하게 손상된 사진 복원이다. 원본 이미지에 계속 잡음을 추가하면 결국 형태를 알아볼 수 없게 된다. 반대로 AI가 현재 상태에서 어떤 노이즈를 제거해야 하는지 반복적으로 예측하면 다시 원본 형태에 가까워질 수 있다.
Forward Process에서는 원본 이미지에 노이즈를 점진적으로 추가한다. 시간이 지날수록 이미지 정보는 사라지고 최종적으로 완전한 랜덤 상태에 가까워진다.
반대로 Reverse Process에서는 완전한 노이즈 상태에서 시작해 노이즈 제거 방향을 반복적으로 예측한다. 이 과정을 수십~수백 단계 반복하면 자연스러운 이미지가 생성된다.
대표적인 DDPM 구조는 아래와 같은 형태로 표현된다.
xt=1−βtxt−1+βtϵx_t = \sqrt{1-\beta_t}x_{t-1}+\sqrt{\beta_t}\epsilon
이 식은 시간 단계마다 이미지에 얼마나 노이즈가 추가되는지를 정의한다. 최근에는 Sampling 최적화 기법까지 결합되면서 생성 속도 역시 빠르게 개선되고 있다.
학습 과정은 어떻게 진행될까
Diffusion Model 학습의 핵심 네트워크는 U-Net 구조다. 원래 의료 영상 segmentation 용도로 사용되던 구조지만 현재는 노이즈 복원 네트워크로 활용된다.
노이즈 상태 이미지가 입력되면 U-Net은 현재 단계에서 제거해야 할 노이즈 패턴을 예측한다. Downsampling 과정에서는 특징을 압축하고, Upsampling 과정에서는 세부 정보를 다시 복원한다.
또 하나 중요한 개념은 Time Step이다. 모델은 현재 이미지가 몇 번째 노이즈 제거 단계인지까지 함께 입력받는다.
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)q(x_t|x_{t-1}) = \mathcal{N}(x_t;\sqrt{1-\beta_t}x_{t-1},\beta_t I)
이 구조 덕분에 모델은 각 단계마다 서로 다른 노이즈 제거 전략을 학습할 수 있다.
초기 Diffusion 모델은 생성 속도가 매우 느렸다. 이미지 한 장을 생성하는 데 수백 단계 이상의 반복 계산이 필요했기 때문이다. 특히 고해상도 이미지 생성 시 GPU 메모리 사용량도 상당히 높았다.
최근에는 DDIM, DPM-Solver 같은 Sampling 최적화 기법이 등장하면서 생성 속도가 빠르게 개선되고 있다. 현재는 생성 품질과 추론 속도 사이 균형을 맞추는 방향으로 발전하는 흐름이다.
Stable Diffusion은 기존 Diffusion과 무엇이 다를까
Stable Diffusion의 가장 큰 특징은 Latent Diffusion 구조다.
기존 Diffusion 모델은 픽셀 공간 자체에서 노이즈 제거를 수행했다. 하지만 Stable Diffusion은 이미지를 먼저 잠재 공간(Latent Space)으로 압축한 뒤 그 공간에서 Diffusion 과정을 수행한다.
이 방식 덕분에 연산량이 크게 감소했고 일반 GPU 환경에서도 고품질 이미지 생성이 가능해졌다.
- RTX 3060급 GPU에서도 로컬 실행 가능
- 개인 개발자 파인튜닝 환경 확대
- 오픈소스 기반 모델 커스터마이징 활성화
텍스트 인코더와 Attention 구조 결합 역시 핵심 요소다. 사용자의 프롬프트를 CLIP 기반 텍스트 임베딩으로 변환하고 이를 이미지 생성 과정에 지속적으로 반영한다.
최근에는 SDXL, Flux 같은 차세대 구조들도 등장하고 있다. 단순 이미지 품질 경쟁이 아니라 프롬프트 이해 능력, 손 디테일 안정성, 생성 속도까지 함께 발전하는 흐름이다.
이미지 생성 품질이 급격히 좋아진 이유
최근 Diffusion 성능 향상은 단순히 모델 크기 증가만으로 설명되지 않는다. Attention 구조와 대규모 데이터 학습 방식이 결합되면서 생성 품질이 급격히 개선됐다.
초기 생성 모델은 객체 형태를 대략적으로 맞추는 수준에 가까웠다. 하지만 최신 Diffusion 모델은 광원 방향, 그림자, 재질감, 카메라 구도까지 매우 세밀하게 표현한다.
특히 Cross Attention 구조는 텍스트와 이미지 관계를 정교하게 연결한다. 모델은 프롬프트 안의 단어 의미를 이미지 영역과 대응시키며 생성 과정을 조정한다.
예를 들어 “붉은 우산을 든 사람”이라는 프롬프트가 입력되면 단순히 사람과 우산만 생성하는 것이 아니다. 우산 색상, 위치 관계, 배경 분위기까지 함께 반영한다.
현재 주요 이미지 생성 서비스들은 대부분 Diffusion 계열 구조를 기반으로 최적화를 이어가고 있다. 최근에는 스타일 전이, 인페인팅, 아웃페인팅, ControlNet 기반 구조 제어까지 가능해졌다.
광고 제작, 게임 콘셉트 아트, 제품 디자인 시안 제작 같은 실제 산업 현장에서도 활용 사례가 빠르게 증가하는 중이다.
Diffusion Model은 왜 영상·멀티모달 생성의 중심이 되고 있을까
현재 Diffusion 구조는 이미지 생성 단계를 넘어 영상 생성 분야로 빠르게 확장되고 있다.
영상 생성은 이미지보다 훨씬 복잡하다. 단순히 프레임 품질만 중요한 것이 아니라 시간 흐름에 따른 일관성까지 유지해야 하기 때문이다.
Diffusion 구조는 단계적 복원 방식이라는 특성 덕분에 temporal consistency 문제를 비교적 안정적으로 다룰 수 있다. 최근 연구들은 공간 정보뿐 아니라 시간 축까지 함께 노이즈 제거 대상으로 처리하고 있다.
또한 GPU 비용 문제도 매우 중요하다. 고품질 영상 생성에는 이미지보다 훨씬 많은 연산 자원이 필요하기 때문이다. 그래서 최근 모델들은 생성 품질과 속도 사이 균형을 맞추는 방향으로 발전하고 있다.
멀티모달 분야에서도 Diffusion은 중요한 위치를 차지한다. 텍스트·이미지·오디오·3D 데이터를 하나의 생성 구조 안에서 연결하려는 시도가 계속되고 있다.
특히 3D 생성 분야에서는 NeRF와 Diffusion을 결합하는 연구가 활발하다. 단일 이미지나 텍스트만으로 3D 객체를 생성하는 방향까지 빠르게 발전하는 중이다.
결국 Diffusion Model의 핵심 경쟁력은 “복원 기반 생성”이라는 범용성에 있다. 단순 이미지 생성 기술이 아니라 다양한 형태의 데이터를 단계적으로 생성할 수 있는 공통 생성 프레임워크로 진화하고 있다는 의미다.